
🤝 AidfulAI Newsletter #1: Today’s Notes Are the Core of Your Future AI Assistant

Dear curious minds,
Welcome to the ultimate newsletter for those interested in Artificial Intelligence (AI) and Personal Knowledge Management (PKM). After putting significant effort into it, I am thrilled to take you through the exciting world of these two topics with the first issue of this newsletter.
Major AI News
Filtering the signal from the noise can be challenging due to the overwhelming amount of AI-related news.
💬🌐 ChatGPT Roll-Out of Browser Access to GPT-3.5 model
ChatGPT default mode now includes internet access enabled for many ChatGPT Plus users. It might be needed to put yourself on the waitlist for ChatGPT plugins. However, not every Plus subscriber on the waitlist has the feature yet.
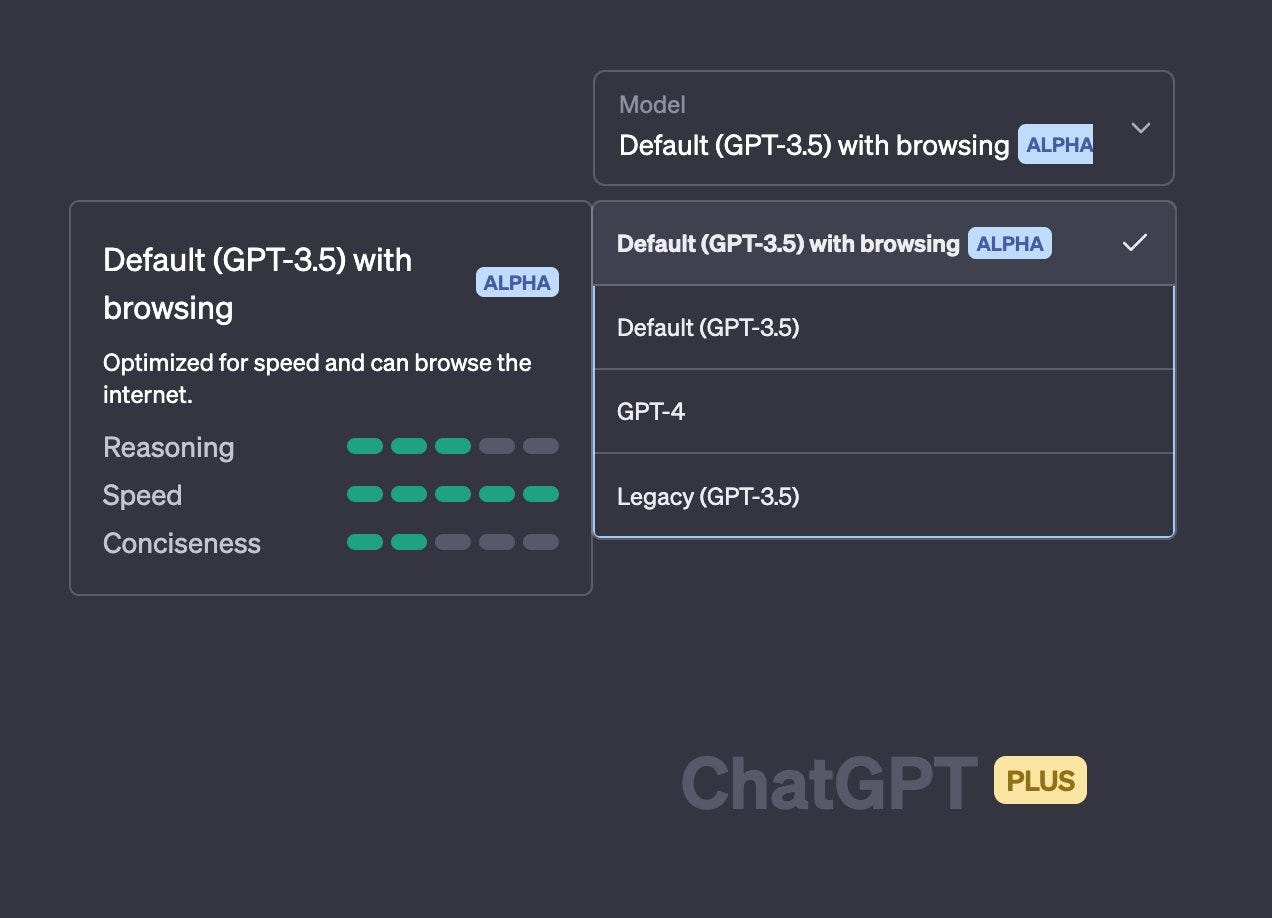
For me, the coolest aspect, but maybe also a limitation, is that the model decides if the question benefits from a web-search or not.
But, why does it not support the newer, and for many tasks better model, GPT-4? Would it be too powerful?
📹💻 Accurate Object Tracking in Videos Will Simplify Video Editing
Building on top of the revolutionary Segment Anything Model (SAM), released as open-source by Meta, the Track Anything Model (TAM) is a new approach that has been developed to track and segment objects in videos with minimal input from humans.

As such, it has the potential to revolutionize video editing by making it faster, more accurate, and more accessible. With its impressive interactive design, the TAM program is ideal for video object tracking and segmentation, enabling users to easily track any object they want with only a few clicks. The TAM program could transform the way video editing is done, making it possible for more people to create professional-quality videos with ease. The developers of the TAM program have made all the resources available to facilitate further research in this exciting field.
Privacy-Friendly AI
Your data should be handled with care and not be used in unintended ways.
🤖🐾 Open-Source ChatGPT Competitor OpenAssistant Live
A new open-source competitor to ChatGPT has been released. OpenAssistant aims to provide the same user experience while preserving privacy. The key to ChatGPT's performance is Reinforcement Learning from Human Feedback (RLHF), which trained it to provide helpful answers to user questions.
To replicate this approach, collecting vast amounts of RLHF data is necessary. OpenAssistant collects this data through a web-based platform with the help of people like you. The crowd-based data collection has generated over 600K human interactions, 150K messages, and 10K+ annotated conversation trees across multiple topics and languages. The first ML models trained on this data have shown promising results.

The code, chat interface, and research paper have been released along with the dataset and trained models. Some restricted models build on top of the LLaMA model from Meta, which was also released for research purposes only.
Compared to ChatGPT, OpenAssistant models can be more human-like, concise, and fun to interact with. A recent user survey shows that preference between ChatGPT and OpenAssistant models was nearly equal, showcasing the potential of the models. However, in my own tests, I found that ChatGPT often provides more helpful responses.
Like ChatGPT, OpenAssistant will soon support plugins which allow the AI to retrieve information dynamically from third-party systems and search the web.
The project is continuing data collection via their web platform, and you can participate to advance privacy-friendly AI and make a difference. To sign up or chat with the released version in an online interface, visit their webpage and create an account. Please note that the sign-up email was marked as spam and did not show up in the inbox.
To get started even faster, you can go to HuggingChat, where an OpenAssistant model is launched by the AI start-up Hugging Face and can be used even without registration.
🤖🦜 Launch of Open-Source Large Language Model StableLM
Stability AI, the company behind the successful open-source text-to-image AI Stable Diffusion, has introduced its first large language model to compete with ChatGPT from OpenAI.
StableLM is open-source and is currently available in an alpha version with 3 and 7 billion parameters. Larger models, with 15 to 65 billion parameters, will be released in the future. Developers can modify and use StableLM base models without restrictions for research or commercial purposes, under a CC BY-SA-4.0 license.
The models with up to 7 billion parameters (GPT-3: 175 billion parameters, GPT-4: unknown) have shown remarkable performance in conversational and coding tasks.
In addition to these base models, with RLHF fine-tuned instruction models were released under a non-commercial CC BY-NC-SA 4.0 license. This restriction exists because these models build on top of other datasets that enforce this. However, Stability AI has announced that it will collaborate with OpenAssistant (see above) to provide completely free instruction-tuned models in the future.
To learn more, please read the announcement blog post.
💬🔏 ChatGPT Privacy Option
Many people are unaware that every conversation they have with ChatGPT is saved and used to train the next version of the AI model.
OpenAI has introduced a new setting for ChatGPT that allows users to turn off the Chat History & Training option. You can access the settings by clicking on the three dots next to your registered email address in the lower-left corner of the ChatGPT window.

Enabling this setting is equivalent to using incognito mode. The chats will still be saved on OpenAI servers for 30 days, but will not be used to train the model. More information is available in the Data Controls FAQ from OpenAI.
This change may address the privacy concerns that have led to the banning of ChatGPT in some countries.
On a side note, this feature could also be the crucial element for some users to share their ChatGPT accounts with others, but 🤫.
PKM and AI
PKM and AI can greatly benefit from each other. In the following paragraphs, you will find some food for thought on this topic.
📖🕚 Read-It-Later Apps in the Age of AI
A 'read-it-later' app allows you to save articles or newsletters for later reading and prevents you from getting distracted from what you are doing at the moment. However, many users initially like such apps, but later become overwhelmed by the large number of articles that pile up.
In my opinion, a mindset shift can help here. One should see the collected articles and newsletters as an archive and not as a task list waiting to be completed. Especially with the advances in generative AI, search capabilities will greatly increase and provide a lot of value.
Moreover, there are read-it-later apps like Reader from Readwise, which already offer features like summarizing single documents or answering questions with the article's content with AI.
In the future, these features will be extended to your entire database of saved articles that resonated with you.
Therefore, collect everything that resonates with you, ideally with a small comment explaining why, and prepare to receive value from AI soon.
If you really need to read an article and want to handle it like a task, you can add it to your Shortlist in Readwise Reader.
📝🤖 Today’s Notes Are the Core of Your Future AI Assistant
Dan Shipper, the co-founder of Every and author of several insightful AI articles, is venturing into new territory with his cohort-based course 'How to Build a GPT-4 Chatbot.'
In 30 days, you will learn how to create an AI assistant that scans your notes, quotes, journal entries, and other personal sources of data to help you write better, make more informed decisions, and generate new ideas. According to Shipper, only basic programming knowledge is required, and ChatGPT will be used as coding assistance during the cohort.
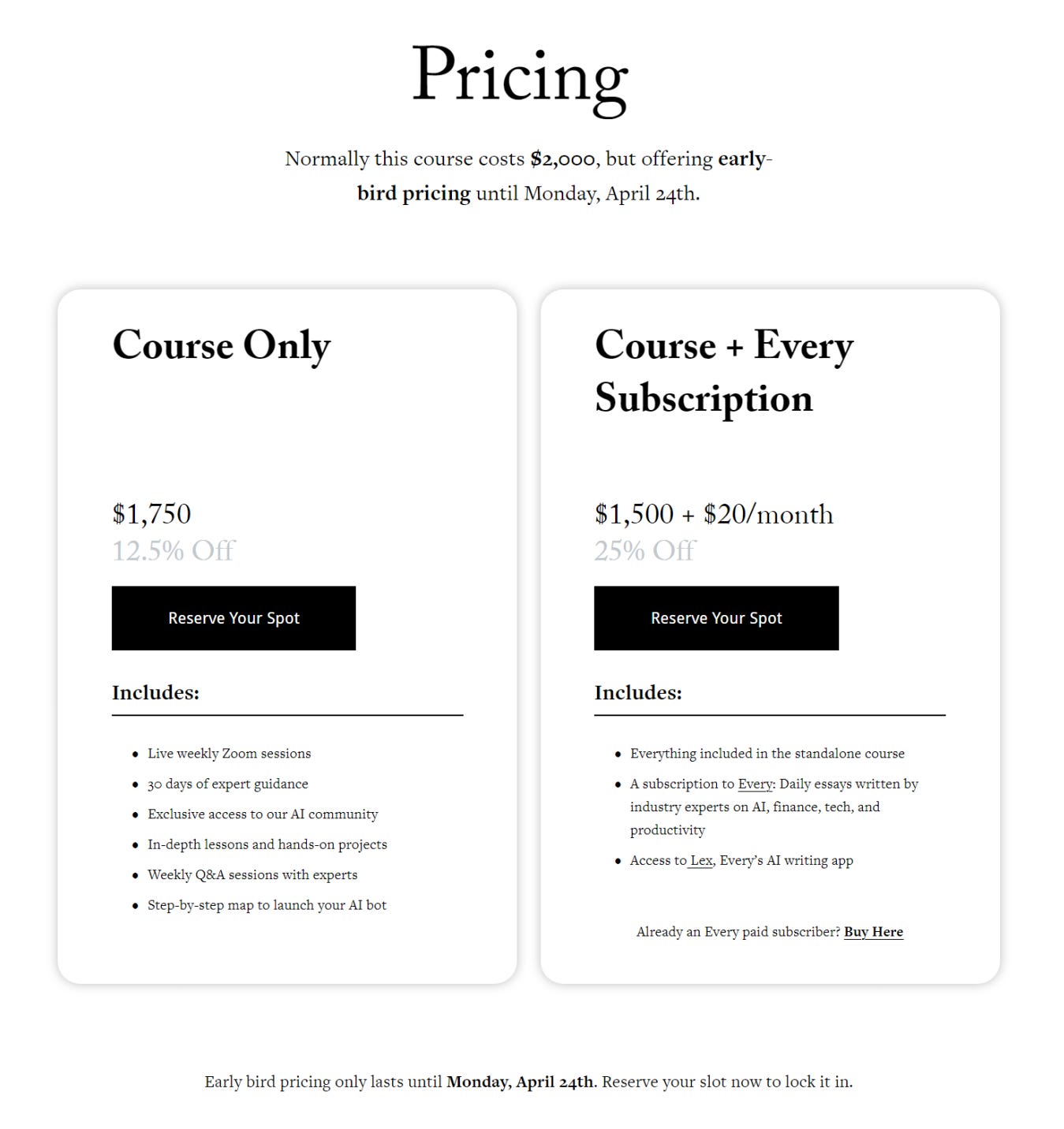
However, with a price tag of $2000, I personally believe the course is quite expensive. Nevertheless, Dan Shipper's cohort is already sold out, but you can still visit the website for further details. The pricing information was removed from the page, but I added it as an image below.
Sarah, who I follow on Twitter, managed to fine-tune an AI with her notes from her note-taking app Obsidian using tutorials provided by OpenAI.
The important takeaway from this section is already stated in the title of this issue: 'Today's Notes are the Core of Your Future AI Assistant.' This means that you should not only consider your future self, but also your future AI assistant when taking notes. It will not matter if you switch between different languages because the AI and future search features will cover them all. It might be helpful to mark, with tags or other indicators, which passages in your notes are quotes or copies from other sources and not created by you.
Furthermore, it will likely be beneficial to record every virtual meeting, as the transcriptions are almost perfect, and you accumulate a vast collection of material to create your tailored AI assistance in the future.
Even if you are not creating an AI from your notes today, my advice is to start collecting information now to create your personalized AI assistant in the future. With everyone having access to AI like ChatGPT, you will only gain an advantage if you have the material to create a tailored AI assistant.
Podcasts
One of the great things about podcasts is that they can be enjoyed while doing other tasks, such as commuting, doing household chores or exercising.
🤖👿 AI Will Likely Kill Us All
Lex Fridman conducts in his podcast episode 371 an interview with Max Tegmark, a physicist and AI researcher at MIT.
Together, they talk about various topics such as intelligent alien civilizations, super intelligent AI, job automation, regulation, consciousness, and an open letter suggesting the pause of Giant AI Experiments. Max Tegmark is rather pessimistic and states that it is likely that AI will kill all humans.
🤖👼 AI Will Likely Be Good For Humanity
Paul Christiano, from the Alignment Research Center, was a guest on the Bankless podcast episode 168.
He is concerned about ensuring that Artificial General Intelligence (AGI) is aligned with human values. He states the task is difficult but not impossible, and highlights various technical solutions to the problem. Furthermore, he only sees a chance of around 20%, that a wrongly aligned AI could cause harm to human existence.
Love the stuff Daniel! Keep at it man.