
🤝 Beyond Paywalls: New Open-Source AI Gems Released
Explore Google's Gemma for text generation & Stability AI's Stable Cascade for image generation.

Dear curious minds,
While the major releases from OpenAI and Google (covered in last week’s issue) have dominated headlines, there's another side of the AI revolution: open-source models. These empower you to run AI directly on your own hardware, free from paywalls and limitations. You are not dependent on a company to keep a service alive. Even if unlikely, OpenAI and Google can block your account or even shutdown their complete AI offering tomorrow.
This week's spotlight shines on two open-source AI gems:
Gemma: Google's open-source model for text generation on your own hardware. It outperforms competitors of the same and even larger size.
Stable Cascade: Stability AI's image generation raises the quality, speed and customization of open-source image generation to a new level.
If nothing sparks your interest, feel free to move on, otherwise, let us dive in!
🤝🤖 Gemma: Googles Open-Source Text Generating AI
As announced in a blog article, Google introduced a new generation of open large language models (LLMs), which are part of their cloud-based Gemini language model family.
Model variants: Gemma 2B and Gemma 7B, with two and seven billion parameters, which differ in hardware requirements, speed and output quality. On top, there are instruction tuned versions which are fine-tuned to follow text instructions even better.
More details about the models are shared in a technical report.
Gemma models can run on various platforms, including laptops, workstations, and Google Cloud.
Terms of use allow responsible commercial usage by organizations of any size (in contrast to Llama from Meta).
Gemma models demonstrate best-in-class performance for their size and are designed to be safe and responsible by filtering sensitive data.

Performance comparison of various open models. Results of multiple benchmarks are grouped and averaged. A more detailed performance breakdown is given in the technical report. [source] The easiest way to get started is by testing the models online in HuggingChat or Perplexity Labs.
If you want to run Gemma locally, two available options are LM Studio v0.2.16 or Ollama v0.1.26. The latter produced initially undesired text outputs, which are now fixed as described in this post.
Google released, besides the models, various training checkpoints and code as well as code to run these models. No training code or training data was released.
My take: Smart move from Google to release smaller versions of their powerful LLMs as open-source and with that compete at the same time with the closed models from Anthropic and OpenAI as well as the open models from Meta, Mistral and others.
As stated in my Gemini Pro 1.5 coverage from last week, Google started to use a Mixture of Experts (MoE) approach. I am looking forward to a Gemma MoE release which competes with Mixtral 8x7B.

🎨🛠️ Crafting Your Vision: Easier AI Art Model Adaptions with Stable Cascade
Stable Cascade is a new text-to-image model launched by Stability AI. It produces state-of-the-art results.

Sample images generations from Stable Cascade. [source] The model is based on the Würstchen architecture, which uses a unique three-stage process to create images. The author of the paper explains the theory behind this approach very nicely in a YouTube video.
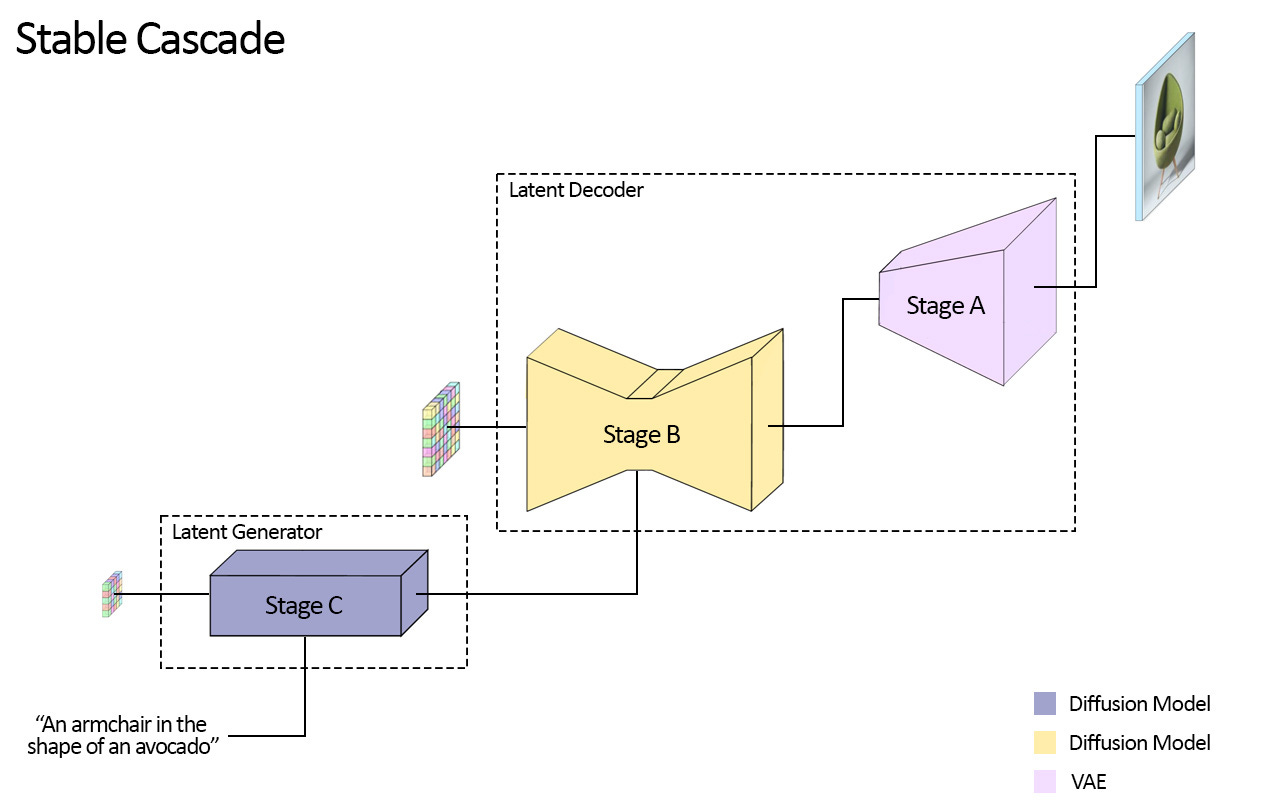
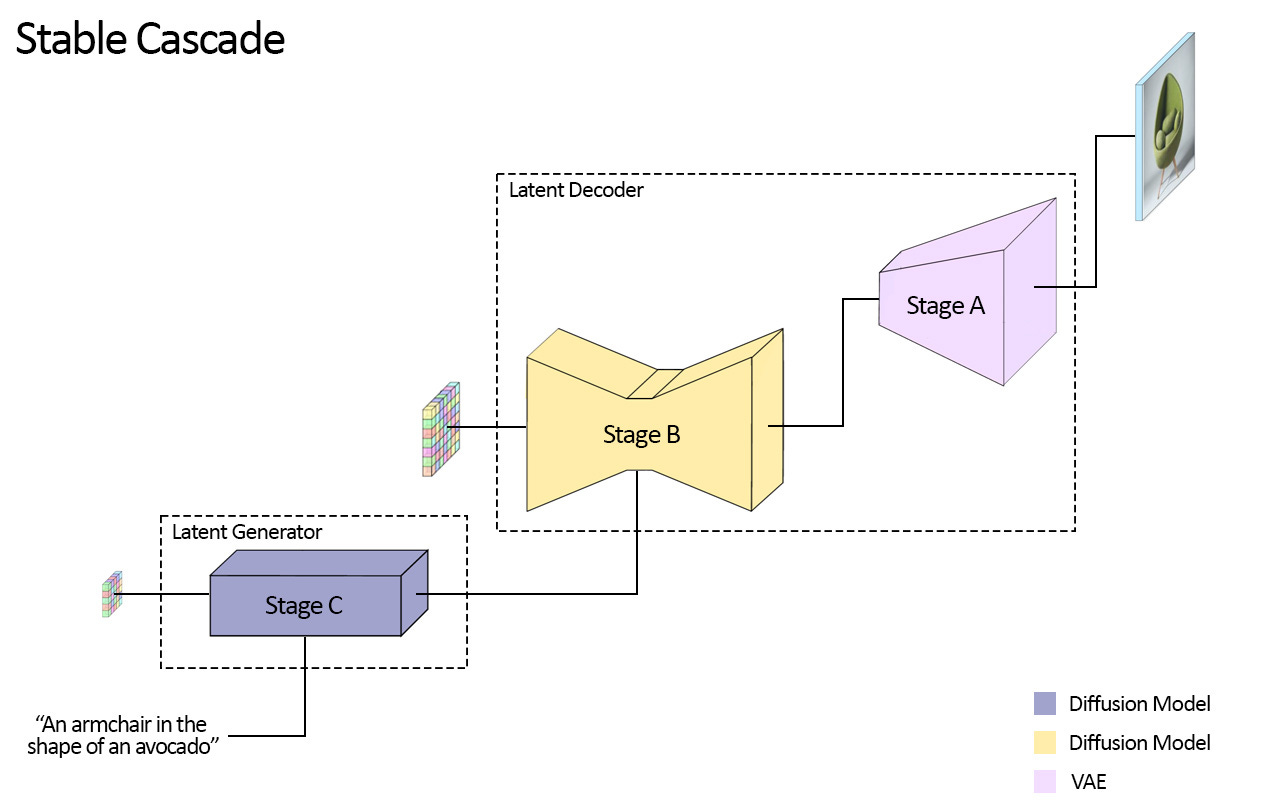
Visualization of the three stage architecture of Würstchen, which is used by Stable Cascade. [source] The results outperform the currently best open-source art generation models, Stable Diffusion XL and Playground V2, based on human evaluations.

Comparison of various open models in a human evaluation. [source] The model is more than twice as fast as Playground v2 and SDXL, but lacks in execution speed behind SDXL Turbo. However, the latter is clearly outperformed in the aesthetic quality of the generated outputs.
It is designed to be easy to train and fine-tune, even on personal computers with a consumer graphic card, as only the small model of Stage C needs to be adapted.
Various ControlNets allow using the model for inpainting / outpainting, edge guidance and super resolution.

Example showing the inpainting and outpainting capabilities of a ContolNet used with Stable Cascade. [source] By training LoRAs (explained in the next section) it is possible to generate new vocabulary for the image generation process.

Example showing how a few images (top row) can be used to generate a LoRA which can be used as a new identifier in the generation process (bottom row). [source] The model is released on GitHub in various sizes for non-commercial use and Stability AI shares, besides the models, training and execution code to use and adjust the model.
My take: Impressive results, even if they are not on the same level as the latest Midjourney release. Especially, the possibility to adapt the model to your own data and guide the generation process is outstanding. One big plus is that Stable Cascade does need way less compute for adaptations than all other so far available methods.
Besides Stable Cascade, which was already released last week, there is now the recent announcement of the Stable Diffusion 3 preview. If you are interested in getting early access, you should join the waitlist.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
💻🔍 Tech Term: Low-Rank Adaptation (LoRA)
Low-Rank Adaptation (LoRA) is a technique used to update or fine-tune pre-trained neural network models for new tasks with minimal changes to the original model structure.
A more detailed breakdown:
In linear algebra, a "low-rank" matrix is a matrix that can be decomposed into the product of two smaller matrices. The rank of a matrix is a measure of its complexity, with lower ranks indicating simpler structures.
LoRA introduces small, low-rank matrices as updates to the weights in certain layers of the neural network. Instead of modifying the original weights directly, which could disrupt what the model has already learned, LoRA adds these small updates on top of the existing weights. This way, the model can adapt to new tasks by learning new information represented by the low-rank matrices.
By focusing on low-rank updates, LoRA limits the number of new parameters the model needs to learn, making the adaptation process more efficient than retraining the entire network or adding large numbers of new parameters.
LoRA is particularly useful for tasks like adapting a language model to understand new terms or concepts, adding new vocabulary to a text-to-image model, or adjusting a model's output to better suit particular requirements. All of this can be done by training and using a LoRA without the need for extensive retraining.
Disclaimer: This newsletter is written with the aid of AI. I use AI as an assistant to generate and optimize the text. However, the amount of AI used varies depending on the topic and the content. I always curate and edit the text myself to ensure quality and accuracy. The opinions and views expressed in this newsletter are my own and do not necessarily reflect those of the sources or the AI models.
This publication is free. If you would like to support me, recommend this newsletter to anyone you think would enjoy it.