
🤝 GPT-4 dethroned in many fair battles

Dear curious minds,
This week’s issues will bring a change to the newsletter, as I will provide a short essay to a topic to provide more original content. This new section will be named “💡 Shared Insight” and is also used to create the title of the newsletter issue.
In this issue:
💡 Shared Insight
The chatbot arena is the best LLM evaluation
📰 AI Update
New LLM from X AI: Grok-1.5
Amazon backs Claude creator Anthropic with $2.75 billion🌟 Media Recommendation
Elon Musk on AGI Safety, Superintelligence, and Neuralink (podcast)
💡 Shared Insight
The chatbot arena is the best LLM evaluation
Large Language Models (LLMs) have taken the world by storm, but are the benchmarks which are published with every new release to measure their performance reliable? From my point of view, they are not, and in the following I explain why we need to rethink how we evaluate these powerful AI systems and name the currently most suitable alternative to classical benchmarks.
A major concern is the potential for bias in training data. If an LLM's training data overlaps with a benchmark test, it could achieve an inflated score that doesn't reflect its real-world capabilities.
But bias isn't the only problem. Companies developing LLMs are becoming increasingly aware of the benchmarks used to judge performance. This creates an environment where models are potentially "gamified" to do well in specific tests, rather than developing a genuine understanding of language.
But even if that is not the case, the benchmark results presented with a new model release are likely not directly comparable as different models are evaluated with different prompting techniques, as shown in the image below from the Gemini Ultra release. Also, the announcement of Grok-1.5 (see next section) shows the same pattern.
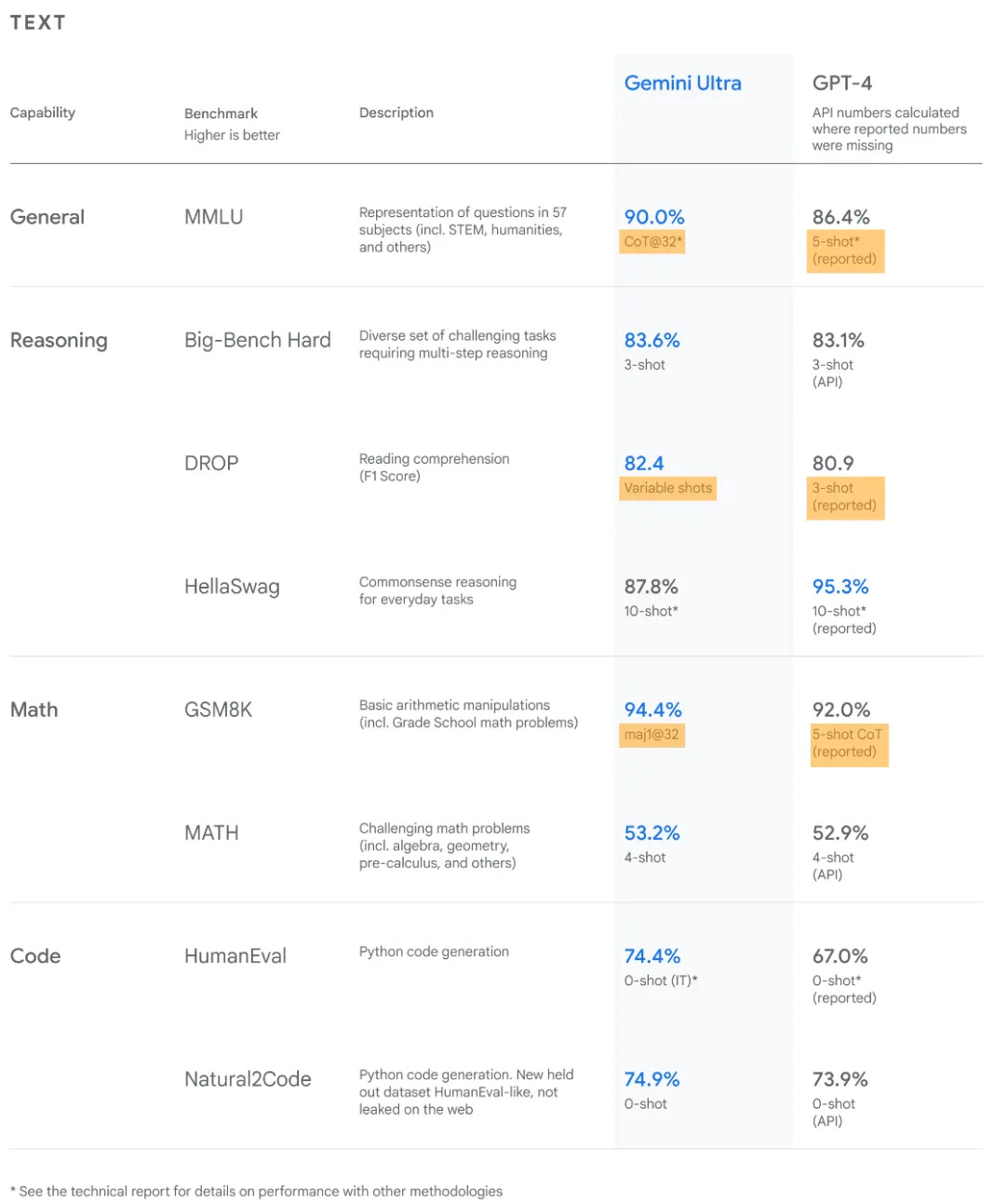
The only alternative I am aware of is the Chatbot Arena, a totally different approach that puts two LLMs against each other on the same prompt. The requester then picks the reply he favors without knowing the models used for their generation. It is an open-source research project developed by members from LMSYS and UC Berkeley SkyLab.

This head-to-head competition provides a more objective rating. Over many comparisons with real-world prompts, each LLM receives an ELO score, similar to the ranking system used in chess. This score reflects the LLM's overall performance, but the leaderboard also states the uncertainty of the calculated scores based on a limited number of responses.
I have followed the chatbot arena leaderboard for quite some time, and the last days were by far the most interesting ones as multiple changes occurred. Firstly and maybe most notable, GPT-4 was dethroned by Opus, the strongest variant of Claude 3. Furthermore, the in comparison to the top places, tiny Starling-LM-7B-beta entered the leaderboard on place 14 and with that in front of the GPT-3.5 model which is currently used in the free version of ChatGPT. Amazing that a model of this size, which was released openly under the commercially friendly Apache-2.0 license, places on such a high rank.
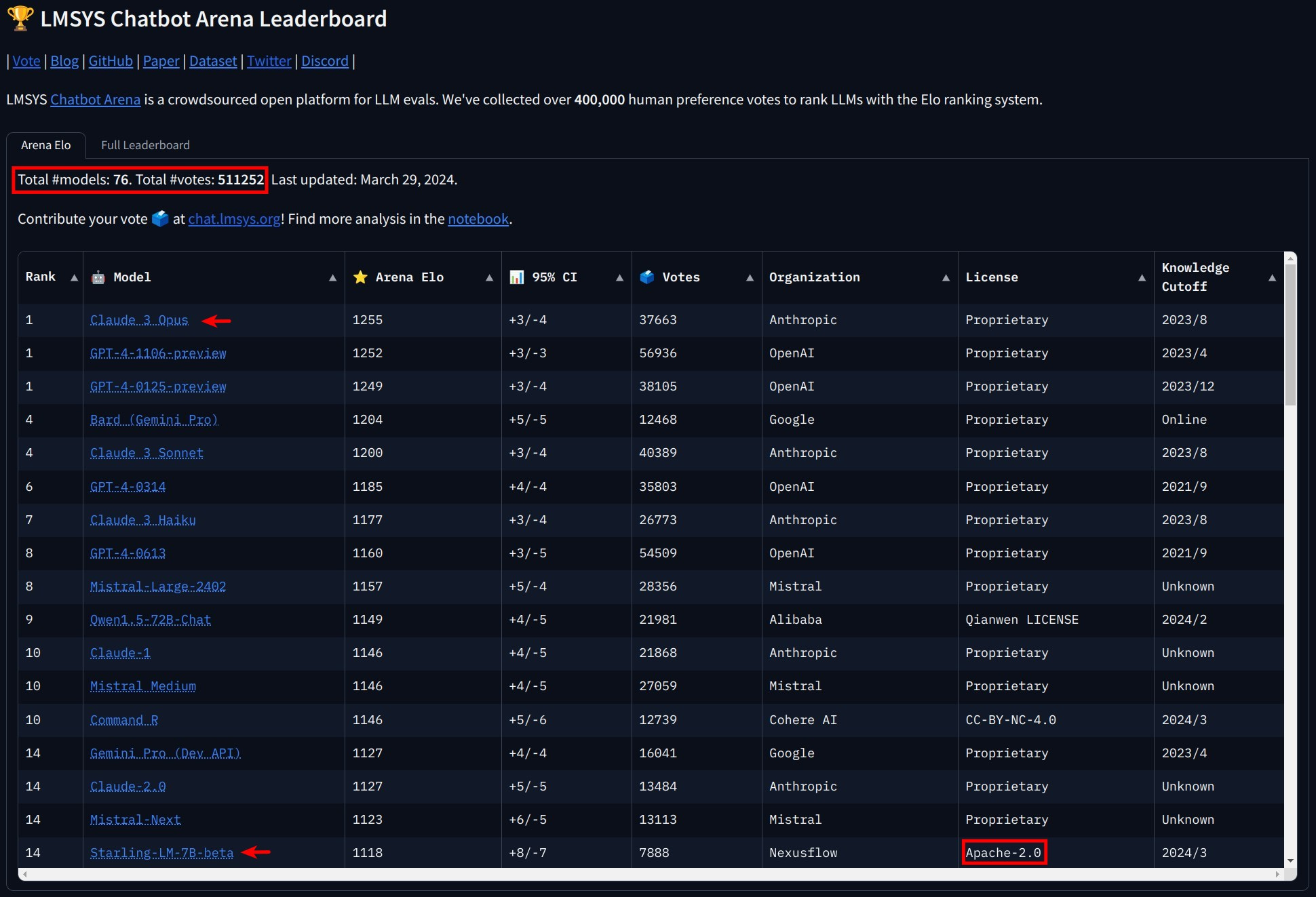
The Chatbot Arena isn't a perfect solution, but it offers a more nuanced and user-centric approach to LLM evaluation. By focusing on real-world prompts and human judgment, it provides a clearer picture of an LLM's ability to perform the tasks we actually care about. If you want to do a deep dive of the platform, the so far collected data and their statistical methods, take a look at the recently released scientific paper from its creators.
📰 AI Update
New LLM from X AI: Grok-1.5
Less than two weeks after the open release of the weights and network architecture Grok-1, the upcoming release of Grok-1.5 was announced.
The shared benchmark results indicate that the gap to the top models in math and reasoning tasks is getting smaller.

Comparison of math and reasoning related benchmarks of the top models. Claude 3 Opus on first place in all benchmarks shown here. [source] Furthermore, they showed perfect retrieval capabilities in their new 128k token context window in the released blog article.
My take: Impressive how fast the X AI team is catching up to the top chatbots. Besides the recent releases, it was announced that the access to Grok will soon be possible via the Premium subscription, instead of currently requiring the more expensive Premium+ tier. Good to have more options.

Amazon backs Claude creator Anthropic with $2.75 billion
A CNBC article states that Amazon said on Wednesday it would invest another $2.75 billion in Anthropic in addition to its initial $1.25 billion.
Amazon will maintain a minority stake in the company and won’t have a board seat.
The deal is based on Anthropic’s last valuation of $18.4 billion, from December 2023.
Over the past year, Anthropic has secured worth more than $7.3 billion in funding. This includes major investment from Google, Sapphire Ventures LLC, and Salesforce.
My take: Generative AI is the hottest tech topic right now. Every big company is trying to get a better positioning by investing in or acquiring AI companies.
🌟 Media Recommendation
Elon Musk on AGI Safety, Superintelligence, and Neuralink (podcast)
Elon Musk was interviewed via a Starlink connection from his private jet by Peter Diamandis.
The podcast episode was livestreamed to his 𝕏 platform, and the recording is also available on YouTube.
Elon states that every company working on foundations models should avoid pushing the AI to lie as this was the lesson learned from the movie “2001: A Space Odyssey”.
Predicting the future of AI is challenging due to the rapid rate of change. Nevertheless, Elon predicts that with a 50% chance, AI will outperform any human in the next year.
Disclaimer: This newsletter is written with the aid of AI. I use AI as an assistant to generate and optimize the text. However, the amount of AI used varies depending on the topic and the content. I always curate and edit the text myself to ensure quality and accuracy. The opinions and views expressed in this newsletter are my own and do not necessarily reflect those of the sources or the AI models.
This publication is free. If you’d like to support me, please recommend this newsletter to anyone you think would enjoy it!