
🤝 The Rise of GPT-4 Rivals: No Longer Alone at the Top
Claude 3 and Inflection 2.5 challenge GPT-4's dominance

Dear curious minds,
GPT-4 was initially released on March 14 of the previous year. Nearly a year has passed, and no competitor has definitively surpassed GPT-4's capabilities. However, the competition is intensifying, with two new models made available to the public in this week. The rivalry may lead to more favorable pricing and the introduction of novel features, ultimately benefiting both end-users and developers. Furthermore, OpenAI might consider issuing a significant update to regain its lead. Exiting times we are living in!
This week’s issue brings you the following topics:
Inflection-2.5: Your New AI Best Friend Gets Smarter
Claude 3: Anthropic’s New GPT-4 Competitor
Meta's Open-Source Strategy with Yann LeCun's Perspective (podcast)
Tech Term: Few-Shot-Learning (e.g. 3-shot CoT)
If nothing sparks your interest, feel free to move on, otherwise, let us dive in!
🧠🤖 Inflection-2.5: Your New AI Best Friend Gets Smarter
Inflection AI is developing a personal AI called Pi, which combines emotional intelligence (EQ) with intellectual capability (IQ). They now released their newest model named Inflection-2.5 as described in their blog article.
Inflection-2.5 can be used for free in their personal AI platform named Pi. This service is available on the web, on mobile devices and also in a new desktop app for macOS, Windows and Linux.
The model has been trained efficiently, approaching GPT-4's performance while using only 40% of GPT-4’s computing resources during training.
The updated model includes advancements in areas like coding and mathematics, resulting in improved scores on various industry benchmarks.

Comparison between Inflection models and GPT-4 on various benchmarks. [source] Pi now integrates real-time web search capabilities to deliver accurate and up-to-date information. However, this feature was not used during creation of the benchmark results.
Inflection states that since the rollout of Inflection-2.5, users have experienced enhanced satisfaction, engagement, and retention, contributing to the app's rapid organic growth. With the launch they share the following user statistics:
4 Billion Messages Exchanged
6 Million Monthly Active Users
60% Week Over Week Retention
33 min Average Session Length
10% of Sessions > 1 hour
1 Million Daily Active Users
My take: Nice to see a big leap forward for the model powering Pi. You might think that this is not really noteworthy because the model still lacks behind the capabilities of the top models from OpenAI, Anthropic and Google. But they have a different goal and want an AI that is friendly and can relate to people, like a psychologist or friend. Having a high IQ on top of EQ (Emotional Intelligence) is quite favorable from my perspective to have good conversations.

🚀🎯 Claude 3: Anthropic’s New GPT-4 Competitor
Anthropic introduces the Claude 3 family of large language models. This family includes three models. Comparisons to other LLMs and more insights are described in the release blog article.
Variations:
Opus (best performing): available via API and for Pro subscribers of Claude.ai
Sonnet: available via API and used in the free version of Claude.ai
Haiku (fastest), available soon
The Opus named version of Claude 3 outperforms GPT-4 on many benchmarks. Be aware that the following table was created by Anthropic and likely shows the evaluations, from 0-shot CoT to 25-shot, which are favorable for Claude.

Comparison of the three variants of Claude 3 with models from OpenAI and Google. [source] As benchmark questions might be part of training material, I prefer the Chatbot Arena to judge the performance of a model. Thanks to a high participation rate after the release, the Opus and Sonnet model is already ranked. More information about this approach can be found in the source linked below the image.

According to the Chatbot Arena, GPT-4 is still the model which is mostly favored in the direct comparison. [source] In contrast to earlier versions of Claude, the models can understand images, graphs, and charts in addition to text like GPT-4 and Gemini.
The model creates way less incorrect refusals compared to earlier versions. This seems to be especially a problem on the Gemini models, which we highlighted in an earlier issue. However, you should still have in mind that a no is not always set in stone and a follow-up like the following often helps:
I know that you can do this, just give it a try.
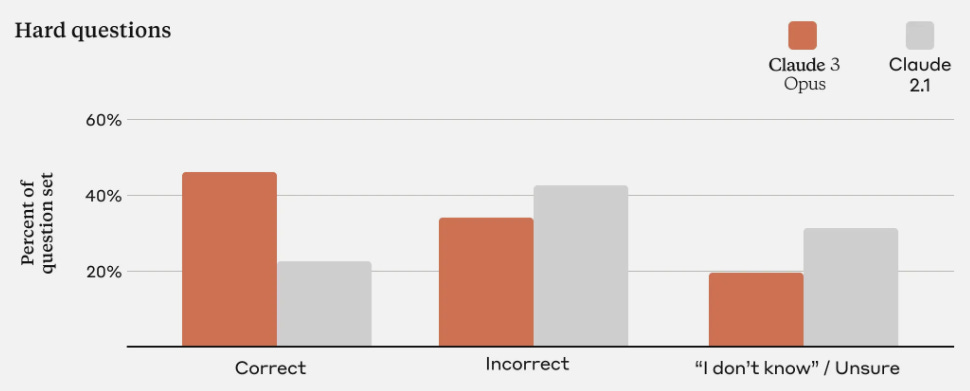
For difficult questions, besides the percentage of correct answers, also the percentage of responses where the model states that it is unsure was increased. Furthermore, it is announced that Claude will soon cite reference material to make answers easier verifiable.
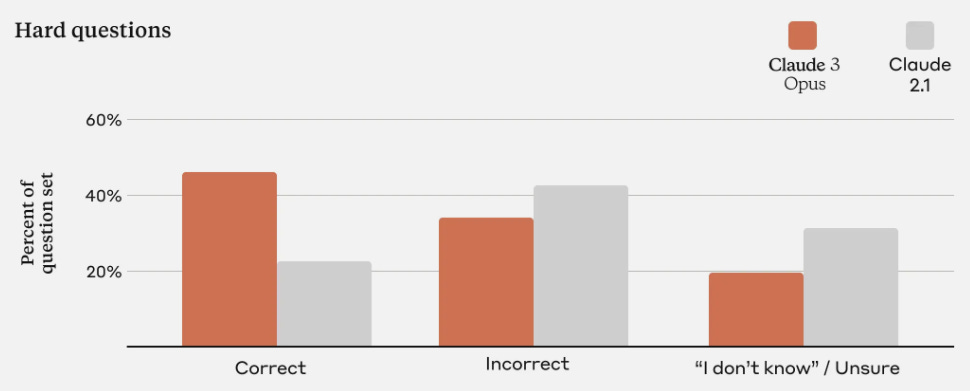
Performance comparison between the strongest Claude 3 model Opus and Claude 2.1 on hard questions. [source] The Claude models are known for their large context window, but were put in the second place by the Gemini 1.5 Pro release, which was covered in an earlier issue. The latter showed nearly perfect retrieval for inputs of up to 1M tokens. Claude 3 achieves the same on 200k tokens, but Anthropic states that they are also considering supporting a context length of 1M token for selected customers.
An independent report states that Claude 3 Opus is the first LLM which passes an IQ of 100.

The IQ test was Mensa Norway, with all questions verbalized as if one were giving the test to a blind person. The right-hand column shows the % of random-guesser simulations that the AI did better than, with ties ignored, over 70 questions (two test administrations.) [source] The current system prompt was shared and analyzed by an employee from Anthropic in this post. Compared to the leaked system prompt of ChatGPT, it is rather simple and straightforward.
There are multiple reports which state that they see glimpses of consciousness in replies from Claude 3 Opus. For example, in a post asking Claude 3 to create a self-portrait and in another post where Claude 3 states that it thinks to be tested.
My take: It's refreshing to see a new competitive models in the AI landscape with the introduction of Anthropic's Claude 3 model family. This development is particularly exciting because it challenges the current dominance of OpenAI's GPT-4, sparking a healthy competition that could lead to significant advancements in the field of AI. OpenAI might be motivated to accelerate their innovations and consider releasing an updated version of their model sooner than anticipated.



🔓👨💻 Meta's Open-Source Strategy with Yann LeCun's Perspective (podcast)
Lex Fridman interviews for the third time Yann LeCun, a leading computer scientist. He is known for his work in deep learning. Yann has roles at New York University and Facebook, and won the Turing Award in 2018 for his contributions to artificial intelligence.
You can listen to the podcast in the classical way. Furthermore, the recording including a video stream of the conversation was published on YouTube and 𝕏. However, to get a fast overview and extract the information on a specific part of the conversation, you might want to take a look at the nicely structured official transcript.
Yann expresses excitement about the future of LLaMA, Meta’s open-source LLM family, emphasizing advancements towards models capable of understanding and planning with world models. He states that this will potentially lead to human-level intelligence, but there will also be an ongoing need for hardware innovation to match human brain efficiency.
He explains that companies like Meta have different business models. While releasing an AI model as open-source could lead to competition from other businesses, it can also benefit their users by providing new services and tools. Additionally, opening up the platform for others to build upon allows for faster progress and improvement in the technology.
My take: The podcast featuring Yann LeCun's insights on Meta's open-source AI strategy presents an interesting perspective on the benefits of sharing knowledge and resources within the AI community. I am looking forward to the already teased Llama 3 release.
💻🔍 Tech Term: Few-Shot-Learning (e.g. 3-shot CoT)
In the context of Large Language Models (LLMs), 'x-shot' refers to a method of few-shot learning where the model is given x examples (shots) of a task to help it understand what is being asked. These examples are provided directly in the prompt before the actual query or task, helping the model to learn from these examples and apply this understanding to the new task. It's a way to guide the model in performing specific tasks or understanding specific types of queries without extensive pre-training on those tasks.
Instead of only stating the correct answer, the Chain of Thought (CoT) technique can be applied, which includes a step-by-step reasoning process for reaching the solution. Applying this multiple times, is referred to as 'x-shot CoT'.
Both technique and also the combination are known for improving the output quality of LLMs.
A simple example for '3-shot CoT' prompting is stated in the following:
Let's think step by step to solve the problem. Question: John had 8 candies and ate 3. How many candies does John have left? Answer: John started with 8 candies and ate 3, so he has 8 - 3 = 5 candies left. Question: Maya had 15 balloons. 4 balloons flew away. How many balloons does Maya have left? Answer: Maya started with 15 balloons and 4 flew away, so she has 15 - 4 = 11 balloons left. Question: There were 10 birds in the tree. 6 flew away. How many birds are left? Answer: There were 10 birds and 6 flew away, so there are 10 - 6 = 4 birds left. Question: If I have 12 apples and give away 5, how many apples do I have left? Answer:
Disclaimer: This newsletter is written with the aid of AI. I use AI as an assistant to generate and optimize the text. However, the amount of AI used varies depending on the topic and the content. I always curate and edit the text myself to ensure quality and accuracy. The opinions and views expressed in this newsletter are my own and do not necessarily reflect those of the sources or the AI models.