
🤝 Understanding the unstoppable rise of deepfakes
Dear curious minds,
The ongoing advancements in AI will change the world we know. Videos were once the source of truth and a reliable source. Deepfakes are nothing new, but their quality has increased drastically and will be harder than ever before to identify them.
In this issue:
💡 Shared Insight
The Future of Lies: How AI Will Make You Question Everything📰 AI Update
Phi-3: Microsoft Brings LLMs to Limited Hardware
Stable Diffusion 3 API Release: Outperforms Competitors
Microsoft's VASA-1: From Single Photo to Realistic Portrait Video
💡 Shared Insight
The Future of Lies: How AI Will Make You Question Everything
The ability to generate realistic, personalized videos with AI is a dangerous development. While the technology holds some promise, the potential for misuse is enormous. We are moving towards a future where videos, once considered reliable sources of information, can be easily manipulated. The last couple of months showed steady progress in the creation of AI video, and the latest development named VASA-1 by Microsoft (highlighted below) shows a concerning level of realism for videos generated from a single input image and audio file. The latter can easily be generated to say anything from a one-minute-long voice recording with the technology offered by Elevenlabs.
The upcoming Deepfakes using these new developments will be more realistic than ever before. These videos show people speaking or acting incorrectly will damage trust in leaders, cause disagreements, and potentially start conflicts. Imagine a made-up video of a political leader making offensive remarks – the damage to their reputation would be immense.
The emerging threat is not just theoretical. Even without public available software, bad actors with enough budget will surely find ways to use existing research to create very realistic malicious content. The knowledge is already out there, and it is only a matter of time until AI video manipulation is as easy to use as ChatGPT, putting this power in the hands of anyone, regardless of their motives.
Not just famous people! These fake videos could be used to hurt anyone. They will spread lies, ruin someone's life, or even trick people out of money. It's scary how easy it will be to fool everyone.
The development of AI-generated videos is a double-edged sword. While it holds some potential benefits for content generation, the dangers are undeniable. Governments will be unable to stop deepfakes from being made or spread. In this new world, we must think critically and learn to detect the small imperfections and artifacts which allow us to identify fake content. But besides that, the most important point is that we remind others to question what they see online.
📰 AI Update
Phi-3: Microsoft Brings LLMs to Limited Hardware
There was a new release by Microsoft announced for their Phi family of small LLMs. The first model Phi-3 mini was openly released by Microsoft in April 2024 with the MIT license.
This 3.8B version makes it possible to run a decent LLM on many devices with limited compute. This includes PCs without GPUs or even smartphones.
In contrast to Llama 3 (covered in the last issue) which was trained on a gigantic dataset for a very long time, Phi-3 especially profits from a highly optimized dataset which combines curated real and simulated data.
There are versions of it with a 4K and 128K token context windows size.
The technical report states that the model does not contain much factual knowledge due to its size limitation and is restricted to the English language.
Besides the release Phi-3 mini version with 3.8B parameters, Microsoft announced Phi-3-small (7B) and Phi-3-medium (14B).
So far, the model is not listed in the Chatbot Arena Leaderboard, but the released benchmarks show a really high performance for its small size.
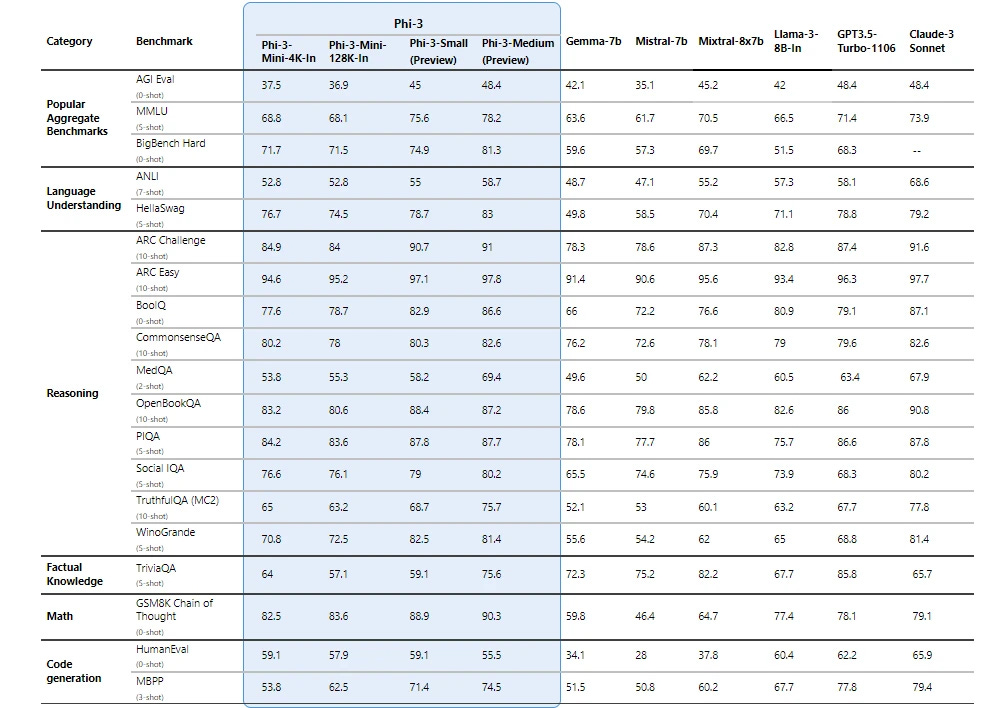
My take: Besides running it on limited hardware with at least 3 GB of memory, the model is a viable option to save compute if you run a task for which you verified that this small model is performing well. Furthermore, the small size makes it a good starting point for modifications like fine-tuning.
Stable Diffusion 3 API Release: Outperforms Competitors
Stable Diffusion 3 (SD3) and Stable Diffusion 3 Turbo, which were already announced in the week after the Stable Cascade release, are available now via the Stability AI Developer Platform API.
The published research paper shows that based on human preference evaluations outperforms state-of-the-art text-to-image generation systems such as DALL·E 3 (integrated in ChatGPT) and Midjourney v6 in text rendering (typography) and prompt following while being on par in visual aesthetics.

Registering with a Google account will give you 25 free credits, which can be used to generate images with SD3 (6.5 credits) and SD3 Turbo (4 credits). The prices are quite competitive as you get 1000 credits for $10 and with that 1 credit corresponds to 1 cent. For comparison, generating an image with DALL·E 3 via the OpenAI API costs 8 cent in the same size.
There are already various ways to use the API. The simplest way to get started is the Fireworks AI platform, which was announced as a partner in the API release blog article.

Stability AI plans to allow self-hosting of the model weights with a membership in the near future. The latter is free for non-commercial usage.
My take: Nice to have a competitive, open alternative to the closed state-of-the-art models. Sadly, there is no release of the model weights yet. However, the pricing for image generations sounds fair and will replace my DALL·E 3 usage if the quality is as high as the released images and benchmarks suggest.
Microsoft's VASA-1: From Single Photo to Realistic Portrait Video
Microsoft's VASA-1 is a new AI model that generates realistic portrait videos from a single photo and audio file. The results are not perfect, but very impressive as they are very accurate and feel natural in the regards of lip sync, facial features, and head movement.

There are various parameters as the viewing direction, head offset and emotion, which can be set to control the output.

The technical paper states that the current realization does not work for the upper body. Furthermore, the lack of a full 3D face model and non-rigid elements like hairs and clothing leads to some artifacts in the generated videos.
The approach is currently not publicly available. As stated in the release blog article, there are so far no plans for an upcoming public or developer release in any form.
The model generates 512x512 pixel images at 45 frames per second using a desktop-grade NVIDIA GeForce RTX 4090 GPU in about 2 minutes.
My take: An earlier issue highlighted VLOGGER by Google, but VASA-1 creates a way higher quality and realism. There are still some artifacts if you look closely, but it gets way more difficult to identify generated videos. Scary!
Disclaimer: This newsletter is written with the aid of AI. I use AI as an assistant to generate and optimize the text. However, the amount of AI used varies depending on the topic and the content. I always curate and edit the text myself to ensure quality and accuracy. The opinions and views expressed in this newsletter are my own and do not necessarily reflect those of the sources or the AI models.