
🤝 Why your AI agents should use local LLMs

Dear curious mind,
Welcome to this week’s issue of Aidful News, where we explore the latest in open-source AI and how it empowers your knowledge work. This might be the last Aidful News issue, as I plan to rebrand the newsletter to “Cloudless-AI,” but I will tell you more about that next week.
In this issue:
💡 Shared Insight
Your AI Agent Should Use Local LLMs to Protect Your Data
📰 AI Update
Magistral-Small-2509: Mistral’s Compact Reasoning Model with Vision
DeepSeek-V3.1-Terminus: Enhanced Stability and Agent Performance
Collection of Qwen Model Releases and Updates
EmbeddingGemma: Google’s New Efficient Embedding Model
🌟 Media Recommendation
Podcast: Bookworm - Applying Book Lessons to Life
💡 Shared Insight
Your AI Agent Should Use Local LLMs to Protect Your Data
Most big players in the AI space give paying customers the option to opt out of your data being used for training their next models. But the reality is that your data still leaves your system and is stored on their cloud servers. There’s no guarantee about how this data will be used in the future.
The only foolproof way to ensure data privacy is to keep data under your control. This means running AI models on your own hardware. While this might seem more complex than using cloud-based solutions, it’s the only way to guarantee your data remains truly private.
The Evolving AI Landscape
Currently the performance gap between cloud-based foundation models (OpenAI, Anthropic, Google, xAI) and open-source models with shared weights is closing. Despite the extreme compute requirements for training state-of-the-art models, especially Chinese companies are sharing the results of their investments openly.
While cloud-based models still lead in nearly all benchmarks, the real question is:
Will this performance gap matter to end users in the near future?
Looking Ahead
As we move towards AI agents, which take over and work in multiple steps on a task for you, the paradigm is shifting. Instead of relying on one massive model to handle everything, agents will break down complex tasks into smaller, specialized subtasks. This shift presents three significant advantages for open-source models:
Specialization: Smaller, focused open-source models can excel at specific tasks.
Fine-tuning: Open weights allow customization for specific use cases.
Privacy: Complete control over data and processing.
While cloud-based solutions offer convenience today, the future might favor a more distributed approach with specialized open-source models. As AI agents become more popular, the ability to run these models locally while maintaining data privacy could become a crucial advantage.
Organizations that start preparing for this shift now by exploring open-source solutions and building infrastructure for local model deployment will be able to protect their data while leveraging AI’s full potential.
📰 AI Update
Magistral-Small-2509: Mistral’s Compact Reasoning Model with Vision
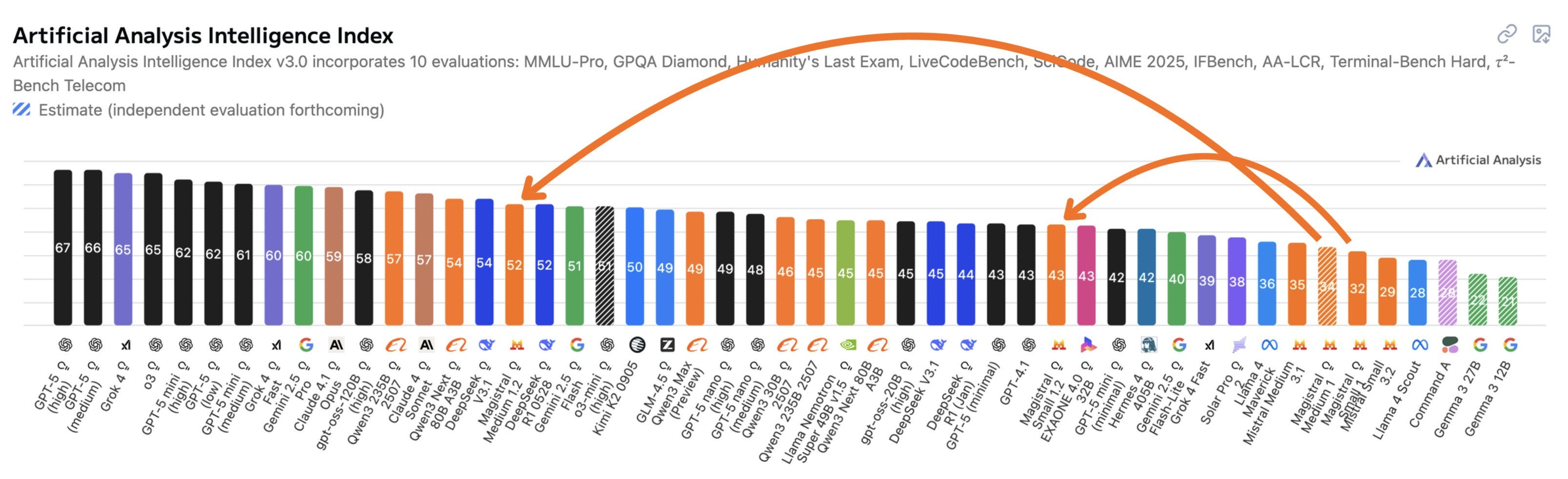
Mistral AI has released updated versions of Magistral Small and Medium, but only the Small version as an open-weight model under the Apache 2.0 license. The Medium version is accessible via their API and chat platform.
Magistral-Small-2509 is a 24 billion parameter reasoning model that builds on the Mistral Small 3.2 foundation with enhanced capabilities for long-chain reasoning and multimodal inputs. This model is strong in mathematics, coding, and general tasks, surpassing its predecessor versions. A key unique aspect is its integration of vision capabilities, allowing it to analyze images alongside text for tasks like document understanding or visual reasoning. With a 128k context window and support for 24 languages, it runs efficiently on consumer hardware like a GPU with 24 GB VRAM or 32GB RAM MacBook after quantization.
DeepSeek-V3.1-Terminus: Enhanced Stability and Agent Performance
DeepSeek has updated their V3.1 model to DeepSeek-V3.1-Terminus, focusing on improved language consistency by reducing Chinese-English mix-ups and random characters. The update also enhances agent capabilities, particularly for code and search tasks, resulting in more stable and reliable outputs across benchmarks compared to the previous version. This model is available on their app, web platform, and API, with open-source weights provided for further development.
Collection of Qwen Model Releases and Updates
Alibaba has released and updated various models, but not all of them as open-weight models. The non-closed releases are:
Qwen3-Omni-30B-A3B Series: Three open-weight multimodal models (Instruct, Thinking, Captioner) with native support for text, images, audio, and video. The models feature real-time responses in written and spoken words across 119 languages. [source]
Qwen3-VL-235B-A22B Series: The most powerful vision-language model in the Qwen series, with Instruct and Thinking editions offering superior text understanding, visual perception, long context (up to 1M), and advanced features like visual agents, coding from images, and enhanced OCR in 32 languages. [source]
Qwen3-4B Toolcalling: A fine-tuned 4B parameter model optimized for function calling, available in GGUF format, requiring only 6GB VRAM. [source]
Qwen-Image-Edit Updated: Alibaba has updated Qwen-Image-Edit to support multi-image inputs, enabling more complex and sophisticated image editing tasks by processing multiple images simultaneously. [source]
To be honest, it is nearly impossible to keep up with and explore all the releases from the Qwen team. At the same time, it is super cool to see how they are continuing to increase the capabilities of the models they release as open-weight.
EmbeddingGemma: Google’s New Efficient Embedding Model
Text embeddings are the key that allows LLMs to work efficiently with your own data. They turn your texts and documents into dense vectors that capture meaning, sentiment, and intent. These vectors enable fast similarity search, clustering, classification, and retrieval.
Google released EmbeddingGemma, a compact 308M parameter multilingual embedding model designed for on-device use. Supporting over 100 languages with a 2K context window, it excels in retrieval, clustering, and classification tasks while staying under 200MB RAM.
🌟 Media Recommendation
Podcast: Bookworm - Applying Book Lessons to Life
In the Bookworm podcast, hosts Mike Schmitz and Cory Hixson read a book every two weeks and discuss ways to apply the authors’ lessons to their lives. They are going beyond just reading to focus on practical implementation.
The podcast features engaging conversations where the hosts share their insights and connections to the material, making it relatable and thought-provoking.
My take: I have discovered this as a new favorite podcast and really enjoy the conversations so far, as I can connect deeply with the discussions between Mike and Cory. Having listened to episodes on books I have read and those I have not, I appreciate both equally. If you share my interest in nonfiction productivity books, this podcast is my strong recommendation for selecting your next read, priming yourself before diving in, or gaining different perspectives after finishing a book. It adds a valuable layer to the reading experience by adding different perspectives.
Disclaimer: This newsletter is written with the aid of AI. I use AI as an assistant to generate and optimize the text. However, the amount of AI used varies depending on the topic and the content. I always curate and edit the text myself to ensure quality and accuracy. The opinions and views expressed in this newsletter are my own and do not necessarily reflect those of the sources or the AI models.